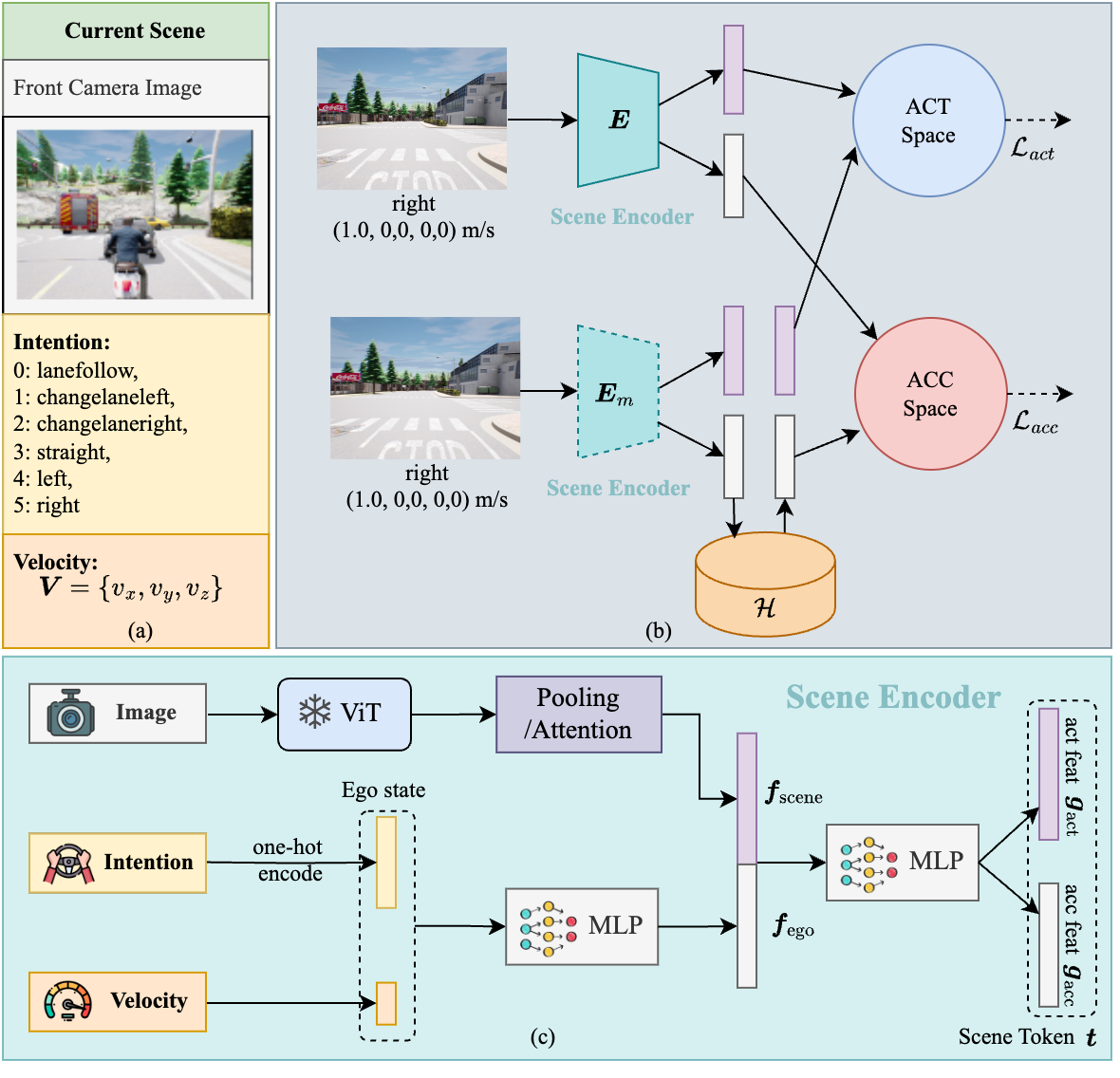
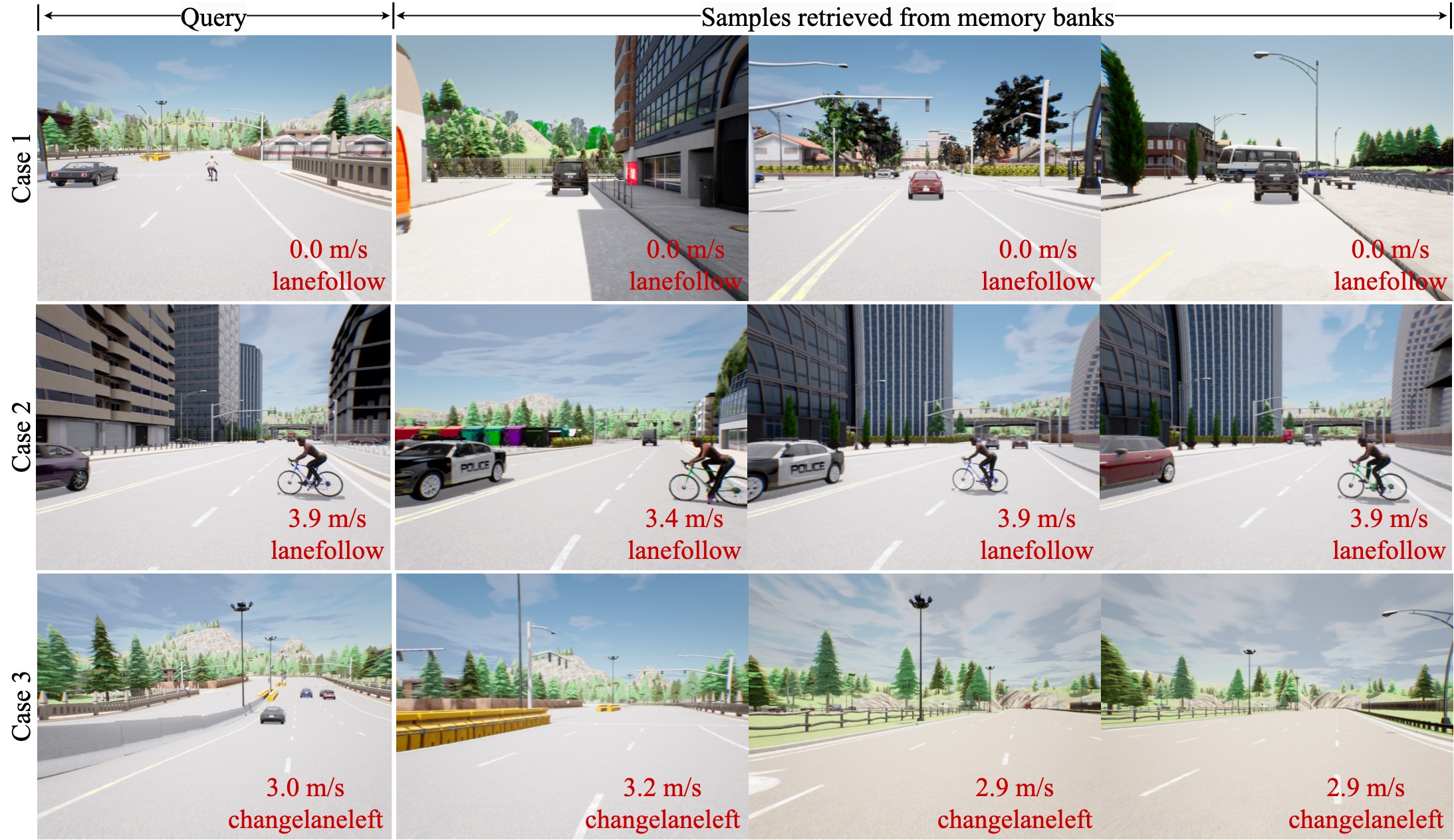
Autonomous driving technology has made significant progress; however, data-driven methods continue to face challenges in complex scenarios due to their lack of reasoning ability. Knowledge-driven autopilot systems have evolved significantly, thanks to the recent popularization of visual language models. Therefore, we propose a novel data-driven framework named LeapVAD. Our method is designed to emulate the human attentional mechanism, selectively focusing on key traffic objects that influence driving decisions. LeapVAD simplifies environmental representation and reduces the complexity of decision-making by describing the attributes of these objects, such as appearance, motion, and risks. Furthermore, LeapVAD incorporates an innovative dual-process decision-making module that mimics the human learning process of driving. This model comprises a Analytic Process (System-II) that accumulates driving experience through logical reasoning without human intervention, and a Heuristic Process (System-I) that develops from this knowledge via fine-tuning and few-shot learning. LeapVAD also includes reflective mechanisms and a growing memory bank, enabling it to learn from past mistakes and continuously improve its performance in a closed-loop environment. We further trained a Scene Encoder network to generate scene tokens, providing a compact representation for the efficient retrieval of target driving experiences. We conducted experiments in two renowned self-driving simulators, Carla and DriveArena. Our method, trained with less data, outperforms other approaches that rely solely on camera input. Furthermore, extensive ablation studies highlight its continuous learning and migration capabilities.




@misc{ma2025leapvadleapautonomousdriving,
title={LeapVAD: A Leap in Autonomous Driving via Cognitive Perception and Dual-Process Thinking},
author={Yukai Ma and Tiantian Wei and Naiting Zhong and Jianbiao Mei and Tao Hu and Licheng Wen and Xuemeng Yang and Botian Shi and Yong Liu},
year={2025},
eprint={2501.08168},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2501.08168},
}
